How to control crawling and indexing
- 19 May 2023
- 6 Minutes to read
- Contributors



- Print
- DarkLight
- PDF
How to control crawling and indexing
- Updated on 19 May 2023
- 6 Minutes to read
- Contributors
- Print
- DarkLight
- PDF
Article Summary
Share feedback
Thanks for sharing your feedback!
There are two methods you can use to control crawling and indexing:
1. Robots.txt
This text file tells crawlers which URLs they can access on your side. Its purpose is to prevent your site from being overloaded with requests or to keep a file off of Google, depending on the file type.
It's essential to take note of the fact that this is not a way for you to hide your pages from Google.
The robots.txt file can be used on:
Web pages
On your end, robots.txt files can be used to manage crawler traffic on your pages and prevent your server from being overwhelmed with requests. Image files, video files, PDFs, and other non-HTML files will be excluded.
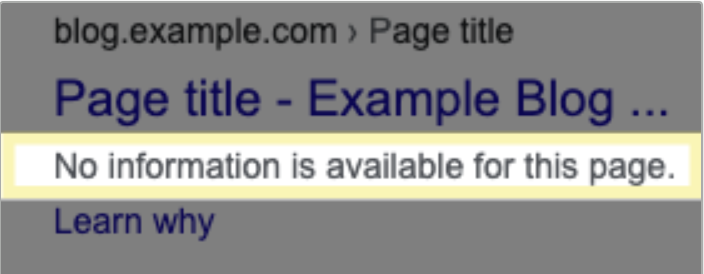
On the other end, an URL blocked with a robots.txt file will still appear in search results, but the content will not have a description.
Media files
The robots.txt file also prevents images, videos, and audio files from showing in Google search results. However, other pages or users can still link to your media content.
If you'd like to remove those too, you can do so as shown in the following articles:
Resource files
You can also use the Robots.txt file to block resource files such as images, scripts, or style files. However, you need to ensure that the missing resource files will not affect your pages before doing so.
Limitations
1. Not all search engines support robots.txt directives
Following the rules described in the robots.txt files is the crawler's choice. If the crawler decides to disobey the rules, it can do so.
In general, well-known crawlers (such as Googlebot) follow the instructions set in the robots.txt file, but other crawlers might not.
In this case, it is also recommended to use other blocking methods such as password-protecting private files. You can read more about this method in this article.
2. Not all crawlers interpret syntax the same way
Regardless of how good the crawler is, they don't all interpret the same syntax. You also need to pay attention to the syntax you use for different crawlers.
You can find more information about the different syntaxes in the following article.
3. Disallowed pages can still be indexed if linked from other sites
Even if the robots.txt file normally prevents the content from being crawled and indexed, it will be crawled and indexed if the URL is linked from other places.
To make sure that does not happen, you'll have to opt for other methods such as password-protecting the files on your server, using the 'noindex' meta tag or response header, or just removing the page entirely.
How to create the file
The robots.txt file can be created in any text editor with UTF-8 encoding.
You cannot use a word processor as it usually saves files in a proprietary format.
Format and location:
- The name must always be robots.txt
- You can only have one robots.txt file per site
- You need to have the file at the root of the website host to which it applies. If, for example, you need to use it for the URL https://www.domain.com/, the file must be located at https://www.domain.com/robots.txt and not at https://www.domain.com/pages/robots.txt.
- The file can be used on a subdomain (https://www.example.domain.com/robots.txt) or non-standard ports (https://www.domain.com:8181/robots.txt)
- The file needs to have UTF-8 encoding
Rules
A rule is an instruction given to the crawler telling it which part of your site can be crawled.
Guidelines that need to be observed:
- You can have one or more groups
- For each group, you'll have multiple instructions arranged, one per line. Each of the groups will begin with a User-agent line that will specify the target of those groups
- A group gives the following information:
- Who the group applies to (the user agent).
- Which directories or files can the agent access.
- Which directories or files that agent cannot access
- The groups are processed from top to bottom. One user agent can only match one rule set, and this will be the first and most specific group that matches a given user agent.
- We start with the assumption that a user agent can crawl any page or directory that is not blocked by a disallow rule.
- All rules are case sensitive
- The beginning of a comment is marked by #
Supported directives for Google's crawlers
- user-agent (required)
- disallow (at least one allow /disallowed)
- sitemap (optional)
Upload the file
Once verified and saved on your computer, the file is ready to be uploaded to the server. Since there is no dedicated tool for this, you need to verify how this can be done according to the server you are using.
Test robots.txt markup
To verify that your robots.txt file is publicly accessible, all you need to do is search the file's location in your browser (https://domain.com/robots.txt). You should see the content of your file. Once this verification is done, you can move to test the markup.
Google offers two options for this:
- The robots.txt tester in Search Console.
- Google's open-source robots.txt library for developers.
Submit it to Google
Once all the steps above are done, Google crawlers will be able to find and use your robots.txt file. There is no other action needed on your side unless you update the file. In this case, you need to refresh Google's cached copy. You can read more about this in the following article.
Example file
Below, you will see an example of a robots.txt file that contains two rules
*User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: http://www.example.com/sitemap.xml*
Details
You can find more information about robots.txt rules in the following Google article.
2. Meta tags
You can use Meta tags at the page level to provide search engines with information about the website to different types of clients. Systems will only process meta tags that they understand, ignoring the rest.
Meta tags are added to the section of your HTML code. Below you'll see such an example:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="Description" CONTENT="Author: A.N. Author, Illustrator: P. Picture, Category: Books, Price: £9.24, Length: 784 pages">
<meta name="google-site-verification" content="+nxGUDJ4QpAZ5l9Bsjdi102tLVC21AIh5d1Nl23908vVuFHs34="/>
<title>Example Books - high-quality used books for children</title>
<meta name="robots" content="noindex,nofollow">
</head>
</html>
You can find the complete list of meta tags processed by Google here.
Good to know
- Both HTML and XHTML-style meta tags can be read by Google regardless of the code used on the page;
- Letter case is not important in meta tags with the notable exception of google-site-verification;
- You can use what meta tags you feel are essential for your site, but you need to keep in mind that Google will ignore the meta tags that it doesn't know.
Inline directives
You can exclude some parts of an HTML page from snippets independently of meta-tags on page level. This is done by adding the HTML attribute data-nosnippet, to one of the following supported HTML tags:
- span
- div
- section
Here is such an example:
\<p>
This text can be included in a snippet
<span data-nosnippet>and this part would not be shown</span>.
\</p>
Google de-indexing
There are two steps that need to be followed in order to de-index pages from Google:
NOINDEX meta tag
The NOINDEX meta tag needs to be added in the header, on every page that should be de-indexed.
The changes will be taken into account as soon as googlebot crawls the pages again. However, the resolution time will depend on how often Google crawls the pages so this process may take up a while.
Manually de-index the pages
This can be done in the Google Webmaster Tools account -> Crawl menu -> 'remove a page from the index' link. The pages can be manually added and Google will immediately crawl them and see the NOINDEX meta tag.
Using robots.txt
The robots.txt file can also be used to tell google not to crawl and index the pages. This is generally used in the case of directories that should not be crawled.
Was this article helpful?